
Three architectural choices, and why almost no one gets all three right.
An MIT study that went viral last year reported that 95% of enterprise AI pilots produced no measurable P&L impact, despite roughly thirty to forty billion dollars of enterprise spend. IBM's 2025 CEO study found only one in four AI initiatives delivered the ROI promised at kickoff. Klarna, which spent 2024 telling the press an AI-powered assistant was doing the work of seven hundred customer service agents, spent 2025 quietly hiring humans back — citing lower-quality outcomes than the human team it replaced.
The headline reads as an indictment of agentic AI. It isn't. It's an indictment of how most agentic AI is being built.
In Issue #1 I wrote that the autonomous finance stack of 2026 is real and that twenty companies are doing the work that matters. In Issue #2 I gave you the five markers CFOs should demand from any vendor before they sign. The fifth marker, a data architecture that compounds over time, is the one that determines whether the purchase is truly sustainable.
This week I take Marker 5 apart. Three architectural choices separate the agents that compound from the ones that plateau. I will name each, tell you why it matters, and walk through why most attempts to build it with general-purpose AI tooling fall short. At the end I will give you an interview script and an architecture stack diagram you can take into your next vendor demo.
Day 1 demos, day 365 stagnation: the architecture problem
Most agentic AI shipped today is a workflow that calls a large language model. The workflow has a fixed shape. The model has a parametric memory frozen the day it was trained. When you ask a question, the workflow gathers context, pastes it into a prompt, and queries the model. The next time you ask a similar question, the workflow does the same thing again. There is no mechanism by which the system gets smarter about your business between question one and question one thousand.
That is fine for summarization or drafting. It is not fine for autonomous finance, where the value comes from learning the contours of your specific vendor master, your specific GL conventions, your specific exception patterns. A stateless workflow plateaus at month three because the things that make it useful for your company never accumulate anywhere. The vendor sells you a demo that works on day 1; on day 365 the system is still working from the same starting point. This is the architecture behind most of the 95% of pilots that produced no measurable P&L impact.
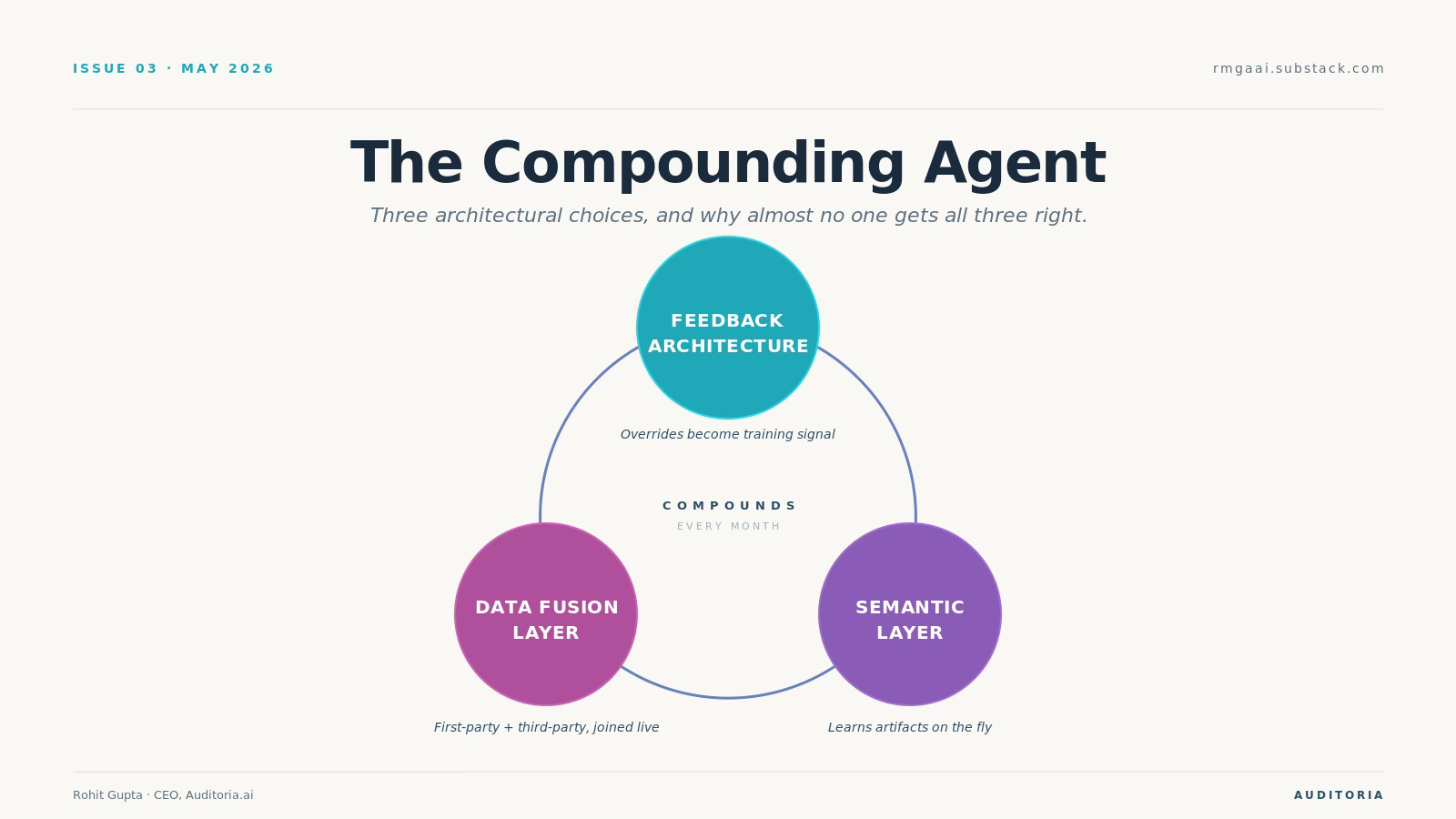
The agents that compound are different. They share three architectural choices.

Choice 1: A first-party / third-party data fusion layer
The system continuously joins your first-party transactional context — invoices, vendor master, payment timing, GL entries, remittance data — with third-party reference data including vendor health signals, industry benchmarks, and macro indicators. Joined live, not as one-time feature engineering.
Why it compounds: signals that do not exist in any single dataset emerge from the join. The system can flag a vendor in your AP queue as statistically about to default, not because you have a column for that, but because the join across thousands of customer-vendor relationships and external signals produces a pattern no individual customer would see in their own data. Each new month sharpens the prediction.
Where DIY falls short: a team that wraps a general-purpose LLM with retrieval over an invoice database can answer questions about invoices; they cannot tell you which vendor is about to fail, because the LLM has no privileged access to third-party data, no ongoing join, and no learned representation of vendor behavior across the ecosystem. Frameworks like LangChain and LlamaIndex are honest about what they are: orchestration toolkits for stitching prompts, retrievers, and tool calls together. They are not data fusion platforms. The internal team that builds on them gets a workflow, not a moat. MIT's 2025 study found that tools built by external vendors succeed twice as often as internal builds; this architectural choice is one of the reasons.
Choice 2: A semantic layer that learns bespoke artifacts on the fly
A semantic layer absorbs and reasons over the data shapes that do not fit the textbook chart of accounts. Side-letter clauses that change revenue recognition for one customer. Carve-out vendors that bill against a different GL string. Legacy conventions inherited from a 2014 acquisition. Industry-specific document types that show up nowhere in the vendor's onboarding wizard. These are the long tail of finance, and where most enterprise AI quietly fails.
Why it compounds: a semantic layer that learns these artifacts on the fly, generalizes the pattern across customers in similar industries, and brings the learning back to your tenant without leaking your data is the layer that makes the system feel like it actually understands your business. Month over month, it accommodates more of your edge cases without requiring schema migration on your side.
Where DIY falls short: a generic LLM has no concept of a side-letter clause until you teach it, and the only ways to teach it at scale are fine-tuning (slow, expensive, doesn't scale per-tenant, and creates data residency problems your CISO will block) or prompt engineering (brittle, doesn't compound). Both fail the test of "does the system get smarter about my business by itself over time?" A semantic layer that auto-learns artifacts requires purpose-built infrastructure: schema inference, cross-tenant generalization with privacy preservation, per-tenant memory, and a continuous learning loop. None of it ships out of the box from any general-purpose AI tool. This is one of the deepest moats in agentic finance, and it is invisible to a CFO until they ask for it directly.
Choice 3: A feedback architecture that turns human overrides into training signal
When an agent makes a decision and a human controller overrides it, what happens to that override? In the systems that compound, the override becomes a labeled training signal that updates the agent's behavior on the next decision of the same type, with a controller-grade audit trail. In the systems that plateau, the override goes into a chat history that nothing reads.
Why it compounds: the override pattern is exactly where your domain knowledge lives. Your controller knows that vendor X's invoices always need a manual GL adjustment because of a 2019 contract. Your AP lead knows that purchase orders from a specific division always require an additional approver. That knowledge is not in any system of record; it lives in the heads of your finance team and surfaces as overrides when the agent gets something wrong. A system that turns overrides into training signal absorbs your team's tacit knowledge. A system that does not is a system you will have to keep correcting forever.
Where DIY falls short: most general-purpose agentic frameworks ship without a controller-grade override log at all; the closest they offer is an unstructured chat history. The ones that do have an override log usually cannot convert overrides into training signal without violating data residency, the model's fine-tuning constraints, or the customer's compliance posture. A structured, auditable override log paired with a learning loop that respects all three constraints is engineering work that takes years to build — and it is precisely the work general-purpose AI tooling does not do for you. This is also the architectural element a Big Four auditor will appreciate most.
Why everyone tries this and most fall short
The pattern is consistent across every failed enterprise AI rollout: an internal team or a horizontal AI tool wraps a general-purpose model with retrieval over the customer's data, ships a demo that looks brilliant on day 1, and plateaus by month three because none of the three architectural choices are actually present. The team built a workflow. They did not build a system. Stateless model calls do not compound.
The companies that ship compounding agents have spent years building the data fusion layer, the semantic layer, and the feedback architecture. None of those come out of the box from any general-purpose AI vendor. The MIT finding that external tools succeed twice as often as internal builds is a polite way of saying this.
The good news for CFOs: this is now a tractable diligence question. You need three questions and the willingness to listen for what the answer reveals:
-
What does your data fusion layer join, and how often?
-
How does your semantic layer learn artifacts that aren't in our schema?
-
Show me yesterday's override log — and the mechanism that turns it into training signal.
Where Auditoria sits

Auditoria's platform is built on all three architectural choices. The data fusion layer, the semantic layer, and the feedback architecture are not features bolted onto one product; they are integral to every agent and every autonomous digital worker we ship — from invoice processing and predictive coding to vendor inquiry handling and customer payment lookup agents. SmartResearch, our continuous cash and spend intelligence layer, is the most visible expression of the data fusion architecture, and customers like Blackbaud, Boddie Noell Inc., and Iowa State University are running the kind of system the three choices describe.
What to do with this
The interview script and the architecture stack diagram are yours. The script is five questions, scoreable on a one-page printable. Ask all five and you will know in 30 minutes whether the vendor you are evaluating sits in the compounders camp or the plateauers camp. Send it to your finance team. Send it to your CIO. Send it to your board.
Next week I am going to pull the camera back and write about the buy-versus-build decision; when CFOs should let internal IT build agentic finance in-house, and when they should not. The three architectural choices in this issue are the spine of that conversation.